論文執筆を査読者からの質問に回答する作業と捉え、
60個程度の質問に回答すると論文がいつの間にかできあがる、という方式で論文執筆を仕組み化しました。
60 Questions and Answers
音声翻訳アプリの多くは、入力される言語が何語であるかをあらかじめ指定する必要があるため、ユーザにとって不便でした。さらに、相手が話している言語が分からない場合には、何語かを指定すること自体が困難でした。 1.5秒程度の短い発話から即座に言語を識別する技術を開発し、NICTの音声翻訳アプリVoiceTraに導入しました。
VoiceTraのダウンロード方法は公式ページをご覧ください。 言語識別機能は、VoiceTraを開き、言語変更をタップ→モードを「自動」に設定することで使用できます。
Solar flare is one of the causes of electromagnetic interference and affects aircrafts' routes. We developed Deep Flare Net based on ResNet and achieved the world's highest performance. The experimental results are shown in this paper.
We published the source code of Deep Flare Net.
Please use the following git command to download it.
$ git clone https://github.com/komeisugiura/defn18.git
The package contains a readme file, which explains how to reprodoce the results.
For more information, please take a look at this GitHub page.
2015年のロボカップ@ホームジャパンオープンで使わ
れたテスト用スクリプトです。英語版と日本語版を含みます。
以下からダウンロード可能です。
https://github.com/komeisugiura/GPSRsentence_generator
2011年のロボカップ@ホームジャパンオープンで使われたテスト用スクリプトです。 以下のような文を生成します。
2010年のロボカップ@ホーム世界大会で使われたテスト用スクリプトです。 以下のような文を生成します。
LinuxでBarrettHandを動かすためのソフトウェアです。
音声合成用コーパスを公開しました。日本語の音声合成用公開コーパスとしては、世界最大級です。 通常の合成用のコーパスでは独話環境で収録しますが、本コーパスは声優掛け合い対話を収録した点が特徴です。 内容の説明はREADMEをご覧ください。 以下の形式のものを、14,179発話含みます。
ALAGIN会員は無料でダウンロード可能です。詳細なダウンロード条件については、 ALAGINのページをご覧ください。
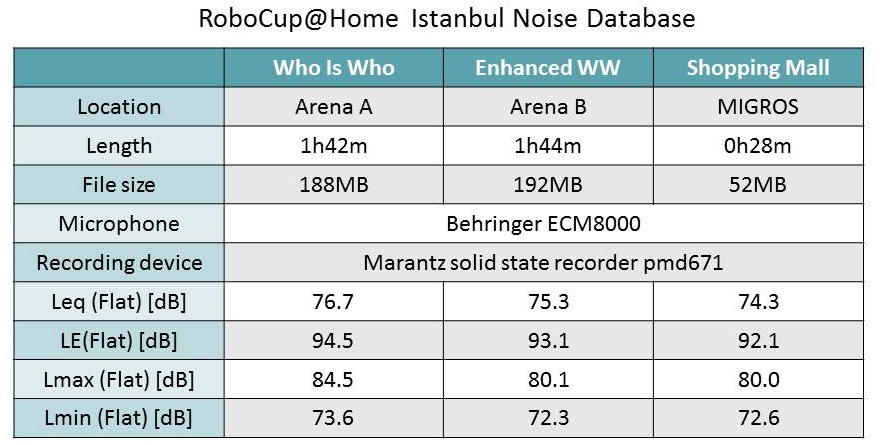
音声ファイルをダウンロードし、実験室で再生しながらロボットの音声認識性能 の評価を行ってください。 ロボカップ@ホームの騒音環境がシミュレートできます。
Rospeex On-Cloudは10ヵ国語に対応したクラウド型音声コミュニケーションツールキットです。ROS(Robot Operating System)上で動作するので、音声認識・合成・対話処理機能を容易にロボットに組み込み可能です。 Rospeexには、On-Cloud版とOn-Premise版の2種類があります。 Rospeex On-Cloudは、2013/9/1-2018/9/30の期間中、お試し版として無料登録不要で公開していました。 Rospeex On-Premiseは、「インターネットに接続できない、クラウド上に音声を送信したくない、自社サーバ上でカスタマイズしたい」という用途に最適です。提供状況については、個別にお問い合わせいただければ、と思います。
API(Pythonまたは C++)を用いて10行程度で簡単な対話を実現できます。自然で親しみやすい音声の合成が可能な非モノローグ音声合成にも一部対応しています。
サービスロボット向けのクラウド型音声合成を、2013/9/1-2018/9/30の期間中、お試し版として無料登録不要で公開していました。 合成音声作成に使用したコーパスを、「NICT声優対話コーパス」として公開しました。
#!/usr/bin/env python3
# coding: utf-8
"""
Python3 sample code for rospeex TTS
"""
import base64
import json
import requests
URL = "http://the_service_was_discontinued"
def main():
databody = {"method": "speak",
"params": ["1.1",
{"language": "ja", "text": "この声を再生します",
"voiceType": "F128", "audioType": "audio/x-wav"}]}
response = requests.post(URL, data=json.dumps(databody))
tmp = json.loads(response.text)
wav = base64.decodestring(tmp["result"]["audio"].encode("utf-8"))
with open("out.wav", "wb") as f:
f.write(wav)
if __name__ == "__main__":
main()
#!/usr/bin/env python2
# coding: utf-8
"""
Python2.7 sample code for rospeex TTS
"""
import base64
import urllib2
import json
URL = "http://the_service_was_discontinued"
def main():
databody = {"method": "speak",
"params": ["1.1",
{"language": "ja", "text": "こんにちは", "voiceType": "*", "audioType": "audio/x-wav"}]}
request = urllib2.Request(URL, json.dumps(databody))
response = urllib2.urlopen(request).read()
tmp = json.loads(response)['result']['audio']
wav = base64.decodestring(tmp.encode('utf-8'))
with open("out.wav", "wb") as f:
f.write(wav)
if __name__ == "__main__":
main()
Linux以外ではROSを使うことが難しいことから、他のOSで利用するための音声認 識単体のみサービスを公開していました。現在は公開を終了しています。
#!/usr/bin/python3
# coding: utf-8
# Python3サンプルコード
"""
Usage: python3 sample.py input.wav
"""
import sys
import base64
import json
import requests
URL = "http://the_service_was_discontinued"
if __name__ == "__main__":
argv = sys.argv
with open(argv[1], "rb") as f: # read a wav file
wav = f.read()
b64encoded_wav = base64.b64encode(wav).decode("utf-8")
databody = {"method": "recognize",
"params": ("ja",
{"audio": b64encoded_wav, "audioType": "audio/x-wav", "voiceType": "*"})}
response = requests.post(URL, data=json.dumps(databody))
json_obj = json.loads(response.text)
print(json_obj["result"])
# -*- coding: utf-8 -*-
# Python2.7サンプルコード
"""
Usage: python sample.py input.wav
"""
import sys
import base64
import json
import urllib2
# Cloud-based speech recognition URL
URL = "http://the_service_was_discontinued"
def read_wavfile(filename):
with open(filename,'rb') as rf:
wav = rf.read()
return wav
def post_to_recognizer(wav):
buf = base64.b64encode(wav)
json_data = { "method":"recognize",
"params":( "ja",
{"audio":buf, "audioType":"audio/x-wav", "voiceType":"*" } ) }
json_obj = json.dumps(json_data)
req = urllib2.Request(URL, json_obj)
cont = urllib2.urlopen(req).read()
return cont
def print_text(json_str):
json_obj = json.loads(json_str)
print json_obj['result'].encode('utf-8')
if __name__=='__main__':
argv = sys.argv
wav = read_wavfile(argv[1])
recognition_result = post_to_recognizer(wav)
print_text(recognition_result)

iPhone, iPod touch, iPadで使用できます。 2010年に構築した音声対話システム(京都観光案内)の、副産物的アプリを作りました。 研究で収集したデータを使った、観光スポット推薦アプリです。 2013/1/1時点で2万ダウンロードされています。 現在、京都が対象ですが、他のスポットや地域にも広げられれば、と考えています。 本アプリのデータベースや手法の活用に興味がある方は、ぜひご連絡ください。
[2013/03/13追記]
京都観光Navi(京都市観光局)に京のおすすめ
のアルゴリズムが導入されました。
[2018/06/1追記]
公開が終了しました。
[2015/07/31追記]
京のおすすめの公開を終了しました。